In this lab, I will look at 3 different approaches that deals with audio volume.
This is the 3 approaches that the course provided:
Three approaches to this problem are provided:
1. The basic or Naive algorithm (
vol1.c). This approach multiplies each sound sample by 0.75, casting from signed 16-bit integer to floating point and back again. Casting between integer and floating point can be expensive operations.2. A lookup-based algorithm (
vol2.c). This approach uses a pre-calculated table of all 65536 possible results, and looks up each sample in that table instead of multiplying.3.A fixed-point algorithm (
https://wiki.cdot.senecacollege.ca/wiki/SPO600_Algorithm_Selection_Labvol3.c). This approach uses fixed-point math and bit shifting to perform the multiplication without using floating-point math.
First, I will try to predict which is the fastest one.
After I looked at all three solutions, I prefer to say solution 3 is the fastest one because it used bitwise operation to make the division.
for (x = 0; x < SAMPLES; x++) {
data[x] = (data[x] * vf) >>16;
}This will be extremely fast to the CPU, but the accuracy may be affected.
To identify the time of every solution used, I decided to use linux system call to record the time.
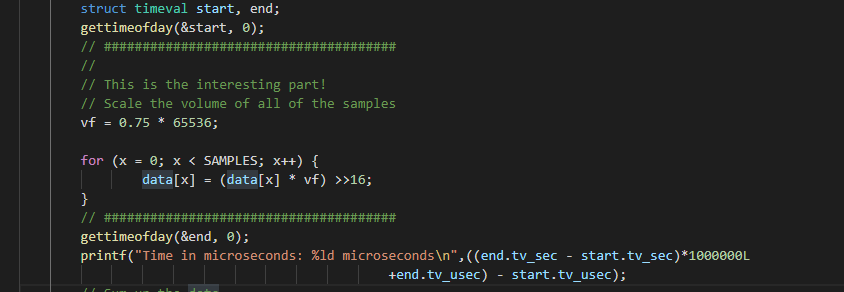
Time of sample 500000000 on israel(in microsecond, us):
vol1 1460840
vol2 2579299
vol3 754098
If I ran the programs again, the time will be a little bit different but most likely the differences are very tiny so that we can ignore it.
The reason why there is such differences is that the OS may dealing with other stuff so that the program cannot take 100% CPU resources.
On israel, vol2 is the slowest one. However, when I try to run the same programs on xerxes, vol1 is the slowest one. Maybe the different instruction set resulted in this. vol3 is the fastest on both israel and xerxes.
Memory usage:
I use ‘top’ to monitor the memory usages.

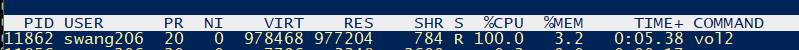

According to the data, the memory usages of the 3 solutions were almost same.
The things that shocks me is that the same code(logic) might have different performance on different architectures. The CPU is general use chip so that it can do all the stuff, but the hardware architecture does affect the program performance. So that if there are some specific usage logic and the code is hard to be optimized, create a architecture that only process this logic may be able to improve the performance effectively.
