- Examine the code:
for (int i = 0; i < plane_zoomlevels(images[0], beginZL, endZL); i++) {
std::pair<int, int> pzl = plane_zoomlevel(images[0], beginZL, endZL, i, ranges);
int p = pzl.first;
int z = pzl.second;
if (options.chroma_subsampling && p > 0 && p < 3 && z < 2) continue;
if (!default_order) metaCoder.write_int(0, nump-1, p);
if (ranges->min(p) >= ranges->max(p)) continue;
int predictor = (the_predictor[p] < 0 ? find_best_predictor(images, ranges, p, z) : the_predictor[p]);
//if (z < 2 && the_predictor < 0) printf("Plane %i, zoomlevel %i: predictor %i\n",p,z,predictor);
if (the_predictor[p] < 0) metaCoder.write_int(0, MAX_PREDICTOR, predictor);
if (endZL == 0) v_printf_tty(2,"\r%i%% done [%i/%i] ENC[%i,%ux%u] ",(int)(100*pixels_done/pixels_todo),i,plane_zoomlevels(images[0], beginZL, endZL)-1,p,images[0].cols(z),images[0].rows(z));
Properties properties((nump>3?NB_PROPERTIESA[p]:NB_PROPERTIES[p]));
if (z % 2 == 0) {
// horizontal: scan the odd rows, output pixel values
for (uint32_t r = 1; r < images[0].rows(z); r += 2) {
pixels_done += images[0].cols(z);
if (endZL == 0 && (r & 257)==257) v_printf_tty(3,"\r%i%% done [%i/%i] ENC[%i,%ux%u] ",(int)(100*pixels_done/pixels_todo),i,plane_zoomlevels(images[0], beginZL, endZL)-1,p,images[0].cols(z),images[0].rows(z));
for (int fr=0; fr<(int)images.size(); fr++) {
const Image& image = images[fr];
if (image.seen_before >= 0) { continue; }
uint32_t begin=(image.col_begin[r*image.zoom_rowpixelsize(z)]/image.zoom_colpixelsize(z)),
end=(1+(image.col_end[r*image.zoom_rowpixelsize(z)]-1)/image.zoom_colpixelsize(z));
for (uint32_t c = begin; c < end; c++) {
if (alphazero && p<3 && image(3,z,r,c) == 0) continue;
#ifdef SUPPORT_ANIMATION
if (FRA && p<4 && image(4,z,r,c) > 0) continue;
#endif
ColorVal guess = predict_and_calcProps(properties,ranges,image,z,p,r,c,min,max,predictor);
ColorVal curr = image(p,z,r,c);
#ifdef SUPPORT_ANIMATION
if (FRA) {
if (p==4 && max > fr) max = fr;
if (guess>max || guess<min) guess = min;
}
#endif
assert (curr <= max); assert (curr >= min);
coders[p].write_int(properties, min - guess, max - guess, curr - guess);
}
}
}
} else {
// vertical: scan the odd columns
for (uint32_t r = 0; r < images[0].rows(z); r++) {
pixels_done += images[0].cols(z)/2;
if (endZL == 0 && (r&513)==513) v_printf_tty(3,"\r%i%% done [%i/%i] ENC[%i,%ux%u] ",(int)(100*pixels_done/pixels_todo),i,plane_zoomlevels(images[0], beginZL, endZL)-1,p,images[0].cols(z),images[0].rows(z));
for (int fr=0; fr<(int)images.size(); fr++) {
const Image& image = images[fr];
if (image.seen_before >= 0) { continue; }
uint32_t begin=(image.col_begin[r*image.zoom_rowpixelsize(z)]/image.zoom_colpixelsize(z)),
end=(1+(image.col_end[r*image.zoom_rowpixelsize(z)]-1)/image.zoom_colpixelsize(z))|1;
if (begin>1 && ((begin&1) ==0)) begin--;
if (begin==0) begin=1;
for (uint32_t c = begin; c < end; c+=2) {
if (alphazero && p<3 && image(3,z,r,c) == 0) continue;
#ifdef SUPPORT_ANIMATION
if (FRA && p<4 && image(4,z,r,c) > 0) continue;
#endif
ColorVal guess = predict_and_calcProps(properties,ranges,image,z,p,r,c,min,max,predictor);
ColorVal curr = image(p,z,r,c);
#ifdef SUPPORT_ANIMATION
if (FRA) {
if (p==4 && max > fr) max = fr;
if (guess>max || guess<min) guess = min;
}
#endif
assert (curr <= max); assert (curr >= min);
coders[p].write_int(properties, min - guess, max - guess, curr - guess);
}
}
}
}
if (endZL==0 && io.ftell()>fs) {
v_printf_tty(3," wrote %li bytes ", io.ftell());
v_printf_tty(5,"\n");
fs = io.ftell();
}
}
This is the loop that takes most of time of the program. To examine the loop, I need to know the run time of every loop so that I added timer to the beginning and the ending of the loop. the result is that with the increasing of value ‘i’, the loops takes more time.
Just go though the code, the thing that most likely be effected by value ‘i’ is the
std::pair<int, int> pzl = plane_zoomlevel(images[0], beginZL, endZL, i, ranges);
function.
This function returns a std::pair<int, int>. The function signature is:
std::pair<int, int> plane_zoomlevel(const Image &image, const int beginZL, const int endZL, int i, const ColorRanges *ranges)
it returns a std::pair<int, int> and the tried to assign it’s value to a variable. This may cause the copy constructor and copy assignment operator to be called over and over again. To save the time here, we can allocate the memory on the heap and make the function returns a reference or pointer to avoid call copy constructor or copy assignment operator of std::pair;
I tested it, the program speeded up less than 1% so that not a signification part that affecting performance.
The most important part is the inside loop.
if (z % 2 == 0) {
// horizontal: scan the odd rows, output pixel values
for (uint32_t r = 1; r < images[0].rows(z); r += 2) {
pixels_done += images[0].cols(z);
if (endZL == 0 && (r & 257)==257) v_printf_tty(3,"\r%i%% done [%i/%i] ENC[%i,%ux%u] ",(int)(100*pixels_done/pixels_todo),i,plane_zoomlevels(images[0], beginZL, endZL)-1,p,images[0].cols(z),images[0].rows(z));
for (int fr=0; fr<(int)images.size(); fr++) {
const Image& image = images[fr];
if (image.seen_before >= 0) { continue; }
uint32_t begin=(image.col_begin[r*image.zoom_rowpixelsize(z)]/image.zoom_colpixelsize(z)),
end=(1+(image.col_end[r*image.zoom_rowpixelsize(z)]-1)/image.zoom_colpixelsize(z));
for (uint32_t c = begin; c < end; c++) {
if (alphazero && p<3 && image(3,z,r,c) == 0) continue;
#ifdef SUPPORT_ANIMATION
if (FRA && p<4 && image(4,z,r,c) > 0) continue;
#endif
ColorVal guess = predict_and_calcProps(properties,ranges,image,z,p,r,c,min,max,predictor);
ColorVal curr = image(p,z,r,c);
#ifdef SUPPORT_ANIMATION
if (FRA) {
if (p==4 && max > fr) max = fr;
if (guess>max || guess<min) guess = min;
}
#endif
assert (curr <= max); assert (curr >= min);
coders[p].write_int(properties, min - guess, max - guess, curr - guess);
}
}
}
} else {
// vertical: scan the odd columns
for (uint32_t r = 0; r < images[0].rows(z); r++) {
pixels_done += images[0].cols(z)/2;
if (endZL == 0 && (r&513)==513) v_printf_tty(3,"\r%i%% done [%i/%i] ENC[%i,%ux%u] ",(int)(100*pixels_done/pixels_todo),i,plane_zoomlevels(images[0], beginZL, endZL)-1,p,images[0].cols(z),images[0].rows(z));
for (int fr=0; fr<(int)images.size(); fr++) {
const Image& image = images[fr];
if (image.seen_before >= 0) { continue; }
uint32_t begin=(image.col_begin[r*image.zoom_rowpixelsize(z)]/image.zoom_colpixelsize(z)),
end=(1+(image.col_end[r*image.zoom_rowpixelsize(z)]-1)/image.zoom_colpixelsize(z))|1;
if (begin>1 && ((begin&1) ==0)) begin--;
if (begin==0) begin=1;
for (uint32_t c = begin; c < end; c+=2) {
if (alphazero && p<3 && image(3,z,r,c) == 0) continue;
#ifdef SUPPORT_ANIMATION
if (FRA && p<4 && image(4,z,r,c) > 0) continue;
#endif
ColorVal guess = predict_and_calcProps(properties,ranges,image,z,p,r,c,min,max,predictor);
ColorVal curr = image(p,z,r,c);
#ifdef SUPPORT_ANIMATION
if (FRA) {
if (p==4 && max > fr) max = fr;
if (guess>max || guess<min) guess = min;
}
#endif
assert (curr <= max); assert (curr >= min);
coders[p].write_int(properties, min - guess, max - guess, curr - guess);
}
}
}
}
This takes most of the time.
The code is simple enough so that it is hard to improve the performance by dealing with the code.
However, there are still some other’s way to improve the performance.
The program run on only one thread, so that the CPU frequency is the most important part which affecting performance.
So optimize it, we can cut the picture into frags and run multiple instances at the same time.
Let’s think about this script.
#include <thread>
#include <stdlib.h>
#include <iostream>
#include <string>
#include "timer.h"
using namespace std;
void func(int i){
Timer t;
std::string cmd = "./flif test4k"+to_string(i)+".png out" + to_string(i) +".flif";
t.reset();
t.start();
system(cmd.c_str());
t.stop();
cout << i << " finished in " << t.currtime() << endl;
}
int main(){
Timer t;
t.start();
std::thread t1(func, 1);
std::thread t2(func, 2);
std::thread t3(func, 3);
std::thread t4(func, 4);
t1.join();
t2.join();
t3.join();
t4.join();
t.stop();
cout << "finished in " << t.currtime() << endl;
//combine picture;
//need another program to finish this operation
//...
}
I cut an 8K picture into four 4K pictures, and try to run four FLIF program to cut the four picture at the same time.
If the machine contains 4 psychical cores, the program should be finished with time that is similar as compressing a 4K picture.
The result is:
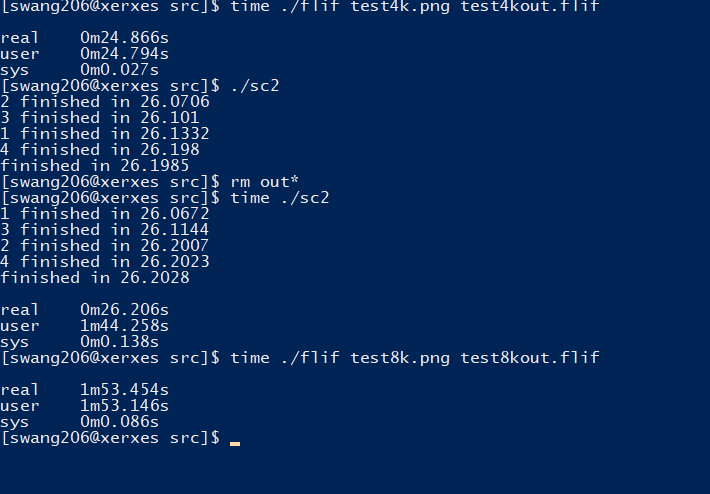
This is actually much faster than previous and match our prediction.
Because this is a lossless compression software so that there are no problems like the issue of calculating the pixel value at the edge of the picture if we cut one picture into fragments and combine them.
Conclusion:
This is my project of SPO600, improving the performance of this open source software. What I learned from the project is that, we should consider the optimization level as early as possible so that the cost of modifying code will not be unacceptable. Also, multiple threading is another effective tool to improve the CPU sensitive programs.
I will post a conclusion post later.
